At mestre Deque-datastrukturer: Den ultimative guide til dobbelt-enderede køer for højtydende computing. Opdag, hvordan deques revolutionerer datahåndtering og algoritmeeffektivitet.
- Introduktion til Deque-datastrukturer
- Kernebegreber: Hvad gør en Deque unik?
- Typer af Deques: Input-restrikteret vs Output-restrikteret
- Nøgleoperationer og deres kompleksiteter
- Deque-implementationer: Arrays vs Lænkelister
- Virkelige applikationer af Deques
- Deque vs Andre datastrukturer: En sammenlignende analyse
- Almindelige faldgruber og bedste praksis
- Optimering af algoritmer med Deques
- Konklusion: Hvornår og hvorfor man skal bruge Deques
- Kilder & Referencer
Introduktion til Deque-datastrukturer
En deque, kort for “dobbelt-enderet kø”, er en alsidig lineær datastruktur, der tillader indsættelse og sletning af elementer fra begge ender – front og bag. I modsætning til standardkøer og stakke, som begrænser operationer til den ene ende, giver deques større fleksibilitet, hvilket gør dem velegnede til en bred vifte af anvendelser såsom planlægningsalgoritmer, palindromkontrol og glidende vinduesproblemer. Deques kan implementeres ved hjælp af arrays eller lænkelister, som hver tilbyder forskellige kompromisser i forhold til tids- og rumkompleksitet.
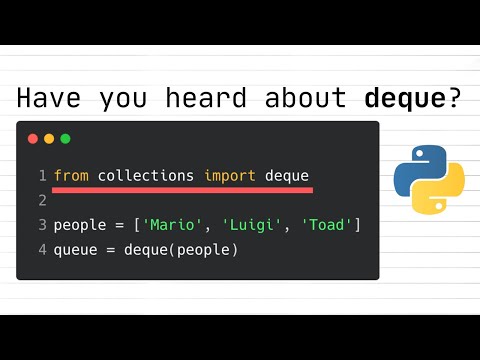
De primære operationer, der understøttes af en deque, inkluderer push_front, push_back, pop_front og pop_back, som alle typisk kan udføres på konstant tid. Denne effektivitet er særligt værdifuld i scenarier, hvor begge ender af sekvensen skal tilgås eller ændres ofte. Mange moderne programmeringssprog tilbyder indbygget support for deques; for eksempel tilbyder C++ containeren std::deque, og Python inkluderer collections.deque i sit standardbibliotek (ISO C++ Foundation, Python Software Foundation).
Deques er vidt brugt i virkelige systemer, såsom implementering af fortrydelsesfunktioner i software, styring af opgaveplanlægning i operativsystemer og optimering af algoritmer, der kræver hyppig adgang til begge ender af en sekvens. Deres tilpasningsdygtighed og effektivitet gør dem til en grundlæggende komponent i værktøjskassen for dataloger og softwareingeniører.
Kernebegreber: Hvad gør en Deque unik?
En deque, eller dobbelt-enderet kø, står ud blandt lineære datastrukturer på grund af dens evne til effektivt at understøtte indsætnings- og sletteoperationer i både front og bag. I modsætning til stakke (som er LIFO – Last In, First Out) og køer (som er FIFO – First In, First Out), tilbyder deques et fleksibelt interface, der kombinerer styrkerne fra begge, hvilket muliggør en bredere vifte af anvendelser. Denne tovejstilgængelighed er den grundlæggende funktion, der gør deques unikke.
Internt kan deques implementeres ved hjælp af dynamiske arrays eller dobbelt-koblede lister. Valget af implementering påvirker præstationskarakteristika: array-baserede deques giver konstant tidsadgang til elementer, men kan kræve ændring af størrelse, mens lænkeliste-baserede deques tilbyder konstant tidsindsættelser og sletninger i begge ender uden overskud fra ændring af størrelse. Denne alsidighed gør det muligt at skræddersy deques til specifikke anvendelseskrav, såsom opgaveplanlægning, fortrydelsesoperationer og glidende vinduealgoritmer.
Et andet kendetegn er, at deques kan være enten input-restrikterede eller output-restrikterede. I en input-restrikteret deque er indsættelse kun tilladt i den ene ende, mens sletning er mulig i begge ender. Omvendt, i en output-restrikteret deque er sletning kun tilladt i den ene ende, mens indsættelse kan finde sted i begge. Denne konfigurerbarhed fremhæver yderligere deques’ tilpasningsdygtighed i forskellige algoritmiske sammenhænge.
Deques er bredt understøttet i moderne programmeringssprog og biblioteker, såsom C++ Standard Library og Pythons collections-modul, hvilket afspejler deres betydning i effektiv data manipulation og algoritme design.
Typer af Deques: Input-restrikteret vs Output-restrikteret
Deques, eller dobbelt-enderede køer, findes i flere varianter tilpasset specifikke anvendelser, hvor de to mest fremtrædende er input-restrikterede og output-restrikterede deques. Disse specialiserede former pålægger begrænsninger på, hvor indsættelser eller sletninger kan finde sted, hvilket påvirker deres operationelle fleksibilitet og præstationskarakteristika.
En input-restrikteret deque tillader indsættelser i kun den ene ende – typisk bagenden – mens den tillader sletninger fra både front og bag. Denne restriktion er nyttig i scenarier, hvor data skal tilføjes i en kontrolleret, sekventiel måde, men kan fjernes fra begge ender efter behov. For eksempel anvendes input-restrikterede deques ofte i planlægningsalgoritmer, hvor opgaver køres i rækkefølge, men kan fjernes baseret på prioritet eller hastende karakter fra begge ender.
Omvendt tillader en output-restrikteret deque indsættelser både i front og bag, men begrænser sletninger til kun den ene ende, normalt fronten. Denne konfiguration er fordelagtig i anvendelser, hvor data kan ankomme fra flere kilder, men skal behandles i en striks rækkefølge, som i bestemte buffer- eller streamingkontekster.
Begge typer af restrikterede deques opretholder den grundlæggende dobbelt-enderede natur af datastrukturen, men indfører operationelle begrænsninger, der kan optimere ydeevnen eller håndhæve specifikke adgangspolitikker. At forstå disse forskelle er afgørende for at vælge den passende deque-variant til en given algoritme eller systemdesign. For yderligere læsning om implementering og anvendelse af disse deque-typer, se GeeksforGeeks og Wikipedia.
Nøgleoperationer og deres kompleksiteter
En dobbelt-enderede kø (deque) understøtter effektiv indsættelse og sletning af elementer i både front og bag. De primære operationer inkluderer push_front, push_back, pop_front, pop_back, front, back og size. Tidskompleksiteten for disse operationer afhænger af den underliggende implementering, typisk enten en dobbelt-koblet liste eller et dynamisk cirkulært array.
- push_front / push_back: Begge operationer tilføjer et element til henholdsvis front eller bag af deque’en. I en dobbelt-koblet liste er disse O(1) operationer, da pegerne blot opdateres. I et cirkulært array er disse også amortiseret O(1), selvom lejlighedsvis ændring af størrelse kan medføre O(n) tid.
- pop_front / pop_back: Disse fjerner elementer fra front eller bag. Ligesom indsættelse er begge O(1) i en dobbelt-koblet liste og amortiseret O(1) i et cirkulært array.
- front / back: Adgang til front- eller bagelementet er altid O(1) i begge implementeringer, da det involverer direkte peger- eller indeksadgang.
- size: At spore antallet af elementer er typisk O(1), hvis der opretholdes en tæller.
Disse effektive operationer gør deques velegnede til anvendelser, der kræver hyppige tilføjelser og fjernelser i begge ender, såsom implementering af glidende vinduealgoritmer eller opgaveplanlægning. For yderligere tekniske detaljer, se cppreference.com og Python Software Foundation.
Deque-implementationer: Arrays vs Lænkelister
Deque (dobbelt-enderet kø) datastrukturer kan implementeres ved hjælp af enten arrays eller lænkelister, som hver tilbyder forskellige kompromisser i forhold til ydeevne, hukommelsesforbrug og kompleksitet. Array-baserede deques, ofte realiseret som cirkulære buffere, giver O(1) tidskompleksitet for indsættelser og sletninger i begge ender, forudsat at ændringer i størrelse er sjældne. Denne effektivitet skyldes direkte indeksering og sammenhængende hukommelsesallokering, hvilket også forbedrer cache-ydeevnen. Dog kan dynamisk ændring af størrelse være kostbar, og arrays kan spilde hukommelse, hvis den allokerede størrelse betydeligt overstiger antallet af gemte elementer. Bemærkelsesværdige implementeringer, såsom Java ArrayDeque, udnytter disse fordele til høj gennemstrømningsscenarier.
Modsat tillader lænkeliste-baserede deques, der typisk implementeres som dobbelt-koblede lister, O(1) indsættelser og sletninger i begge ender uden behov for at ændre størrelse eller flytte elementer. Denne tilgang er fremragende i miljøer, hvor deque-størrelsen ændrer sig uforudsigeligt, da hukommelsen kun allokeres efter behov. Dog medfører lænkelister yderligere hukommelsesoverhead på grund af opbevaring af peger og kan lide af dårligere cache-lokalitet, hvilket potentielt påvirker ydeevnen. C++ std::list og Python collections.deque er fremtrædende eksempler på lænkeliste-baserede deques.
I sidste ende afhænger valget mellem array- og lænkelisteimplementationer af applikationens krav til hukommelseseffektivitet, hastighed og forventede brugsmønstre. Udviklere skal veje fordelene ved hurtig, cache-venlig adgang i arrays mod den fleksible, dynamiske størrelse af lænkelister, når de vælger en deque-implementering.
Virkelige applikationer af Deques
Deque (dobbelt-enderet kø) datastrukturer er meget alsidige og finder omfattende brug i en række virkelige anvendelser på grund af deres effektive støtte til konstant tidsindsætninger og sletninger i begge ender. En fremtrædende anvendelse er i implementeringen af fortrydelses- og genoprettelsesfunktioner i software såsom tekstbehandlere og grafiske designværktøjer. Her kan en deque gemme en historik over brugerhandlinger, hvilket tillader hurtig adgang til både de seneste og de tidligste handlinger for problemfri navigation gennem handlingshistorikken.
Deques er også grundlæggende i algoritmiske problemer, der kræver glidende vindueberegninger, såsom at finde maksimum eller minimum i et bevægeligt vindue over et array. Dette er særligt nyttigt i tidsserieanalyse, signalbehandling og realtidsovervågningssystemer, hvor ydeevne er kritisk, og traditionelle kø- eller stakkestrukturer måske ikke er tilstrækkelige. For eksempel kan problemet med glidende vindue maksimum løses effektivt ved hjælp af en deque, som demonstreret i konkurrenceprogrammering og tekniske interview (LeetCode).
I operativsystemer anvendes deques i opgaveplanlægningsalgoritmer, især i multi-level feedback queue planlæggere, hvor opgaver måske skal tilføjes eller fjernes fra begge ender af rækken baseret på prioritet eller udførelseshistorie (The Linux Kernel Archives). Derudover anvendes deques i bredde-første søgealgoritmer (BFS) til grafgennemgang, hvor noder køres og fjernes fra begge ender for at optimere søgestrategier.
Generelt gør deques’ tilpasningsdygtighed og effektivitet dem uundgåelige i scenarier, der kræver fleksibel, højtydende datahåndtering.
Deque vs Andre datastrukturer: En sammenlignende analyse
Når man evaluerer deque (dobbelt-enderet kø) datastrukturer mod andre almindelige datastrukturer som stakke, køer og lænkelister, fremstår flere nøgleforskelle og fordele. I modsætning til stakke og køer, der begrænser indsættelse og sletning til én ende (LIFO for stakke, FIFO for køer), tillader deques disse operationer både i front og bag, hvilket giver større fleksibilitet for en række algoritmer og anvendelser. Denne tovejstilgængelighed gør deques særligt velegnede til problemer, der kræver både stak-lignende og kø-lignende adfærd, såsom glidende vindueberegninger og palindromkontrol.
Sammenlignet med lænkelister tilbyder deques ofte mere effektiv tilfældig adgang og hukommelsesforbrug, især i array-baserede implementationer. Selvom dobbelt-koblede lister også kan understøtte konstant tidindsættelser og sletninger i begge ender, medfører de typisk en ekstra hukommelsesoverhead på grund af opbevaring af peger og kan lide af dårlig cachepræstation. Array-baserede deques, som implementeret i biblioteker som C++ Standard Library og Python Standard Library, bruger cirkulære buffere eller segmenterede arrays for at opnå amortiserede konstant-tidsoperationer i begge ender, samtidig med at de opretholder bedre lokalitet af reference.
Dog er deques ikke altid det optimale valg. For scenarier, der kræver hyppige indsættelser og sletninger i midten af samlingen, kan datastrukturer som balancerede træer eller lænkelister være at foretrække. Desuden kan den underliggende implementering af en deque påvirke dens præstationskarakteristika, hvor array-baserede deques excellerer i adgangspunkt og hukommelseffektivitet, og lænkeliste-baserede deques tilbyder mere forudsigelig ydeevne til dynamisk ændring af størrelse.
Sammenfattende giver deques et alsidigt og effektivt alternativ til stakke, køer og lænkelister til mange anvendelser, men valget af datastruktur bør vejledes af de specifikke krav til applikationen og de involverede præstationskompromiser.
Almindelige faldgruber og bedste praksis
Når man arbejder med deque (dobbelt-enderede kø) datastrukturer, støder udviklere ofte på flere almindelige faldgruber, der kan påvirke ydeevne og korrekthed. Et hyppigt problem er misbrug af underliggende implementeringer. For eksempel, i sprog som Python, kan brugen af en liste som en deque føre til ineffektive operationer, især når man indsætter eller sletter elementer i begyndelsen, da disse er O(n) operationer. I stedet er det bedst at bruge specialiserede implementeringer såsom Pythons collections.deque, som giver O(1) tidskompleksitet for append- og pop-operationer i begge ender.
En anden faldgrube er at undlade at tage højde for tråd-sikkerhed i samtidige miljøer. Standard deque-implementeringer er ikke iboende tråd-sikre, så når flere tråde får adgang til en deque, bør synkroniseringsmekanismer såsom låse eller tråd-sikre varianter (f.eks. Java’s ConcurrentLinkedDeque) anvendes for at forhindre datakapløb.
Bedste praksis inkluderer altid at overveje de forventede anvendelsesmønstre. For eksempel, hvis der kræves hyppig tilfældig adgang, kan en deque muligvis ikke være det optimale valg, da den er optimeret til operationer i enderne fremfor i midten. Vær desuden opmærksom på hukommelsesforbrug: nogle deque-implementeringer bruger cirkulære buffere, der muligvis ikke skrumper automatisk, hvilket potentielt kan føre til højere hukommelsesforbrug, hvis de ikke administreres korrekt (C++ Reference).
Sammenfattende, for at undgå almindelige faldgruber, vælg altid den passende deque-implementering til dit sprog og anvendelsestilfælde, sørg for tråd-sikkerhed, når det er nødvendigt, og vær opmærksom på præstationskarakteristika og hukommelsesstyringsadfærd for den valgte datastruktur.
Optimering af algoritmer med Deques
Deques (dobbelt-enderede køer) er kraftfulde datastrukturer, der betydeligt kan optimere visse algoritmer ved at tillade konstant tidsindsætninger og sletninger i begge ender. Denne fleksibilitet er særligt fordelagtig i scenarier, hvor både stak- og køoperationer er nødvendige, eller hvor elementer skal styres effektivt fra både front og bag på en sekvens.
Et fremtrædende eksempel er problemet med det glidende vindue maksimum, hvor en deque bruges til at opretholde en liste over kandidater til maksimum for et bevægeligt vindue over et array. Ved effektivt at tilføje nye elementer til bagenden og fjerne forældede elementer fra fronten opnår algoritmen lineær tidskompleksitet, hvilket overgår naive tilgange, der ville kræve indlejrede sløjfer og resultere i kvadratisk tid. Denne teknik anvendes bredt i tidsserieanalyse og realtidsdatabehandling (LeetCode).
Deques optimerer også bredde-første søgning (BFS) algoritmer, især i varianter som 0-1 BFS, hvor kantvægte er begrænset til 0 eller 1. Her tillader en deque algoritmen at presse noder til front eller bag afhængigt af kantvægten, hvilket sikrer optimal gennemløbsorden og reducerer den samlede kompleksitet (CP-Algorithms).
Derudover er deques instrumental i implementeringen af cachesystemer (som LRU caches), hvor elementer hurtigt skal flyttes til fronten eller bagenden baseret på adgangsmønstre. Deres effektive operationer gør dem ideelle til disse anvendelser, som ses i standardbiblioteksimplementeringer som Pythons collections.deque.
Konklusion: Hvornår og hvorfor man skal bruge Deques
Deques (dobbelt-enderede køer) tilbyder en unik kombination af fleksibilitet og effektivitet, hvilket gør dem til et væsentligt værktøj i programmørens værktøjskasse. Deres primære fordel ligger i at understøtte konstant tidsindsættelser og sletninger i begge ender, hvilket ikke er muligt med standardkøer eller stakke. Dette gør deques særligt velegnede til scenarier, hvor elementer skal tilføjes eller fjernes fra både front og bag, såsom i implementering af glidende vinduealgoritmer, opgaveplanlægning eller fortrydelsesoperationer i softwareapplikationer.
At vælge en deque over andre datastrukturer er mest fordelagtigt, når din applikation kræver hyppig adgang og ændringer i begge ender af sekvensen. For eksempel kan deques effektivt styre noder, der skal udforskes i bredde-første søgning (BFS) algoritmer. På samme måde hjælper deques i cachemekanismer som Least Recently Used (LRU) cache med at opretholde adgangsordenen med minimal overhead. Men hvis dit anvendelsestilfælde involverer hyppig tilfældig adgang eller ændringer i midten af sekvensen, kan andre strukturer som dynamiske arrays eller lænkelister være mere passende.
Moderne programmeringssprog og biblioteker giver robuste implementeringer af deques, såsom Pythons collections.deque og C++ Standard Library’s std::deque, hvilket sikrer optimeret ydeevne og brugervenlighed. Sammenfattende er deques den struktur, der skal vælges, når du har brug for hurtige, fleksible operationer i begge ender af en sekvens, og deres anvendelse kan føre til renere, mere effektive kode i et bredt udvalg af applikationer.
Kilder & Referencer
- ISO C++ Foundation
- Python Software Foundation
- GeeksforGeeks
- Wikipedia
- Java ArrayDeque
- The Linux Kernel Archives
- CP-Algorithms