Mastering Deque Data Structures: La guida definitiva a code a doppio termine per l’High-Performance Computing. Scopri come i deques rivoluzionano la gestione dei dati e l’efficienza degli algoritmi.
- Introduzione alle Strutture Dati Deque
- Concetti Fondamentali: Cosa Rende Unico un Deque?
- Tipi di Deques: Deque con Limitazione all’Input vs Deque con Limitazione all’Uscita
- Operazioni Chiave e le Loro Complessità
- Implementazioni Deque: Array vs Liste Collegate
- Applicazioni del Mondo Reale dei Deques
- Deque vs Altre Strutture Dati: Un’Analisi Comparativa
- Errori Comuni e Migliori Pratiche
- Ottimizzazione degli Algoritmi con i Deques
- Conclusione: Quando e Perché Usare i Deques
- Fonti e Riferimenti
Introduzione alle Strutture Dati Deque
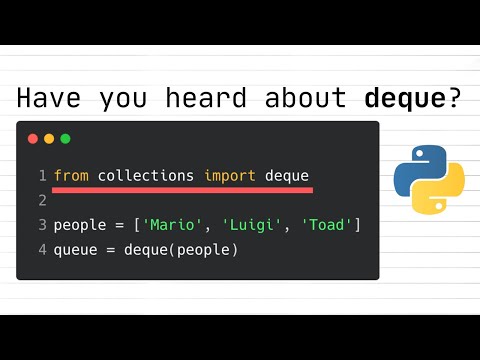
Un deque, abbreviazione di “coda a doppio termine”, è una struttura dati lineare versatile che consente l’inserimento e la cancellazione di elementi da entrambe le estremità—davanti e dietro. A differenza delle code e degli stack standard, che limitano le operazioni a un solo estremo, i deques offrono maggiore flessibilità, rendendoli adatti a una vasta gamma di applicazioni come algoritmi di pianificazione, controllo dei palindromi e problemi di finestre scorrevoli. I deques possono essere implementati utilizzando array o liste collegate, ognuno dei quali offre diversi compromessi in termini di complessità temporale e spaziale.
Le operazioni principali supportate da un deque includono push_front, push_back, pop_front e pop_back, tutte delle quali possono tipicamente essere eseguite in tempo costante. Questa efficienza è particolarmente preziosa in scenari in cui è necessario accedere o modificare frequentemente entrambe le estremità della sequenza. Molti linguaggi di programmazione moderni forniscono supporto integrato per i deques; ad esempio, C++ offre il contenitore std::deque, e Python include collections.deque nella sua libreria standard (ISO C++ Foundation, Python Software Foundation).
I deques sono ampiamente utilizzati nei sistemi del mondo reale, come nell’implementazione delle funzionalità di annullamento nei software, nella gestione della pianificazione dei compiti nei sistemi operativi e nell’ottimizzazione degli algoritmi che richiedono accesso frequente a entrambe le estremità di una sequenza. La loro adattabilità e efficienza li rendono un componente fondamentale negli strumenti degli scienziati informatici e degli ingegneri del software.
Concetti Fondamentali: Cosa Rende Unico un Deque?
Un deque, o coda a doppio termine, si distingue tra le strutture dati lineari per la sua capacità di supportare in modo efficiente operazioni di inserimento e cancellazione sia all’estremità anteriore che posteriore. A differenza degli stack (che sono LIFO—Last In, First Out) e delle code (che sono FIFO—First In, First Out), i deques offrono un’interfaccia flessibile che combina i punti di forza di entrambi, consentendo una gamma più ampia di casi d’uso. Questa accessibilità bidirezionale è la caratteristica principale che rende unici i deques.
Internamente, i deques possono essere implementati utilizzando array dinamici o liste collegate doppiamente. La scelta dell’implementazione influisce sulle caratteristiche delle prestazioni: i deques basati su array forniscono accesso a tempo costante agli elementi ma possono richiedere ridimensionamento, mentre i deques basati su liste collegate offrono inserimenti e cancellazioni a tempo costante a entrambe le estremità senza sovraccarico di ridimensionamento. Questa versatilità consente ai deques di essere personalizzati per requisiti specifici di applicazione, come la pianificazione dei compiti, le operazioni di annullamento e gli algoritmi di finestra mobile.
Un altro aspetto distintivo è che i deques possono essere sia con limitazione all’input che con limitazione all’uscita. In un deque con limitazione all’input, l’inserimento è consentito solo da un’estremità, mentre la cancellazione è possibile da entrambe le estremità. Al contrario, in un deque con limitazione all’uscita, la cancellazione è consentita solo da un’estremità, mentre l’inserimento può avvenire da entrambe. Questa configurabilità migliora ulteriormente l’adattabilità dei deques in vari contesti algoritmici.
I deques sono ampiamente supportati nei moderni linguaggi di programmazione e nelle librerie, come la Libreria Standard C++ e il modulo delle collezioni Python, a testimonianza della loro importanza nella manipolazione efficace dei dati e nel design degli algoritmi.
Tipi di Deques: Deque con Limitazione all’Input vs Deque con Limitazione all’Uscita
I deques, o code a doppio termine, si presentano in diverse varianti adattate a casi d’uso specifici, con le due più prominenti che sono i deques con limitazione all’input e i deques con limitazione all’uscita. Queste forme specializzate impongono vincoli su dove possono avvenire le inserzioni o le cancellazioni, influenzando così la loro flessibilità operativa e le caratteristiche delle prestazioni.
Un deque con limitazione all’input consente inserimenti solo da un’estremità—tipicamente quella posteriore—mentre permette cancellazioni sia dall’estremità anteriore che posteriore. Questa restrizione è utile in scenari in cui i dati devono essere aggiunti in modo controllato e sequenziale, ma rimossi da entrambe le estremità secondo necessità. Ad esempio, i deques con limitazione all’input sono spesso utilizzati negli algoritmi di pianificazione in cui i compiti sono messi in coda in ordine, ma possono essere rimossi sulla base della priorità o dell’urgenza da entrambe le estremità.
Al contrario, un deque con limitazione all’uscita consente inserimenti sia dall’estremità anteriore che posteriore, ma limita le cancellazioni solo a un’estremità, di solito quella anteriore. Questa configurazione è vantaggiosa in applicazioni in cui i dati possono arrivare da più fonti ma devono essere elaborati in un ordine rigoroso, come in determinati contesti di buffering o streaming.
Entrambi i tipi di deques limitati mantengono la fondamentale natura a doppio termine della struttura dati ma introducono vincoli operativi che possono ottimizzare le prestazioni o imporre politiche di accesso specifiche. Comprendere queste distinzioni è cruciale per selezionare la variante di deque appropriata per un dato algoritmo o design di sistema. Per ulteriori letture sull’implementazione e sui casi d’uso di questi tipi di deque, consulta GeeksforGeeks e Wikipedia.
Operazioni Chiave e le Loro Complessità
Una coda a doppio termine (deque) supporta l’inserimento e la cancellazione efficienti di elementi sia all’estremità anteriore che posteriore. Le operazioni principali includono push_front, push_back, pop_front, pop_back, front, back e size. La complessità temporale di queste operazioni dipende dall’implementazione sottostante, tipicamente una lista collegata doppia o un array circolare dinamico.
- push_front / push_back: Entrambe le operazioni aggiungono un elemento alla parte anteriore o posteriore del deque, rispettivamente. In una lista collegata doppia, queste sono operazioni O(1), poiché i puntatori vengono semplicemente aggiornati. In un array circolare, anche queste sono O(1)</strong) in media, anche se un ridimensionamento occasionale può comportare un tempo O(n).
- pop_front / pop_back: Queste rimuovono gli elementi dalla parte anteriore o posteriore. Come per le operazioni di inserimento, entrambe sono O(1) in una lista collegata doppia e O(1)</strong) in media in un array circolare.
- front / back: Accedere all’elemento anteriore o posteriore è sempre O(1) in entrambe le implementazioni, poiché comporta accesso diretto al puntatore o all’indice.
- size: Tenere traccia del numero di elementi è tipicamente O(1) se viene mantenuto un contatore.
Queste operazioni efficienti rendono i deques adatti per applicazioni che richiedono frequenti aggiunte e rimozioni da entrambe le estremità, come l’implementazione di algoritmi a finestra mobile o la pianificazione dei compiti. Per ulteriori dettagli tecnici, consulta cppreference.com e Python Software Foundation.
Implementazioni Deque: Array vs Liste Collegate
Le strutture dati deque (coda a doppio termine) possono essere implementate utilizzando array o liste collegate, ciascuna delle quali offre diversi compromessi in termini di prestazioni, utilizzo della memoria e complessità. I deques basati su array, spesso realizzati come buffer circolari, forniscono una complessità temporale di O(1) per l’inserimento e la cancellazione a entrambe le estremità, assumendo che il ridimensionamento non sia frequente. Questa efficienza è dovuta all’indicizzazione diretta e all’allocazione contigua della memoria, il che migliora anche le prestazioni della cache. Tuttavia, il ridimensionamento dinamico può essere costoso e gli array possono sprecare memoria se la dimensione allocata supera significativamente il numero di elementi memorizzati. Implementazioni degne di nota, come il Java ArrayDeque, sfruttano questi vantaggi per scenari ad alta capacità.
Al contrario, i deques basati su liste collegate, tipicamente implementati come liste collegate doppiamente, consentono inserimenti e cancellazioni O(1) a entrambe le estremità senza la necessità di ridimensionare o spostare elementi. Questo approccio eccelle in ambienti dove la dimensione del deque fluttua in modo imprevedibile, poiché la memoria viene allocata solo secondo necessità. Tuttavia, le liste collegate comportano un sovraccarico di memoria aggiuntivo dovuto all’archiviazione dei puntatori e possono soffrire di una località di cache meno favorevole, influenzando potenzialmente le prestazioni. Esempi prominenti di deques basati su liste collegate sono il C++ std::list e il collections.deque di Python.
Infine, la scelta tra le implementazioni basate su array e su liste collegate dipende dalle esigenze dell’applicazione riguardo all’efficienza della memoria, alla velocità e ai modelli di utilizzo previsti. Gli sviluppatori devono valutare i benefici di un accesso rapido e favorevole alla cache negli array rispetto alle dimensioni flessibili e dinamiche delle liste collegate quando selezionano un’implementazione di deque.
Applicazioni del Mondo Reale dei Deques
Le strutture dati deque (coda a doppio termine) sono estremamente versatili e trovano un ampio utilizzo in una varietà di applicazioni del mondo reale grazie al loro supporto efficiente per inserimenti e cancellazioni a tempo costante da entrambe le estremità. Una delle applicazioni più prominenti è nell’implementazione delle funzionalità di annullamento e ripetizione in software come editor di testo e strumenti di progettazione grafica. Qui, un deque può memorizzare una cronologia delle azioni dell’utente, consentendo un accesso rapido sia alle azioni più recenti che a quelle più vecchie per una navigazione senza soluzione di continuità nella cronologia delle azioni.
I deques sono anche fondamentali nei problemi algoritmici che richiedono calcoli di finestre scorrevoli, come trovare il massimo o il minimo in una finestra mobile su un array. Questo è particolarmente utile nell’analisi delle serie temporali, nell’elaborazione dei segnali e nei sistemi di monitoraggio in tempo reale, dove le prestazioni sono critiche e le strutture di coda o stack tradizionali potrebbero non essere sufficienti. Ad esempio, il problema del massimo nella finestra scorrevole può essere risolto in modo efficiente utilizzando un deque, come dimostrato nella programmazione competitiva e nelle interviste tecniche (LeetCode).
Nei sistemi operativi, i deques sono utilizzati negli algoritmi di pianificazione dei compiti, soprattutto negli scheduler a feedback multi-livello, dove i compiti possono dover essere aggiunti o rimossi da entrambe le estremità della coda in base alla priorità o alla cronologia di esecuzione (The Linux Kernel Archives). Inoltre, i deques sono impiegati negli algoritmi di ricerca in ampiezza (BFS) per l’attraversamento dei grafi, dove i nodi vengono messi in coda e rimossi da entrambe le estremità per ottimizzare le strategie di ricerca.
In generale, l’adattabilità e l’efficienza dei deques li rendono indispensabili in scenari che richiedono una gestione dei dati flessibile e ad alte prestazioni.
Deque vs Altre Strutture Dati: Un’Analisi Comparativa
Quando si valuta la struttura dati deque (coda a doppio termine) rispetto ad altre comuni strutture dati come stack, code e liste collegate, emergono alcune differenze e vantaggi chiave. A differenza di stack e code, che limitano l’inserimento e la cancellazione a un solo estremo (LIFO per gli stack, FIFO per le code), i deques consentono queste operazioni sia nella parte anteriore che posteriore, offrendo maggiore flessibilità per una varietà di algoritmi e applicazioni. Questo accesso bidirezionale rende i deques particolarmente adatti per problemi che richiedono comportamenti sia simili a stack che a coda, come i calcoli a finestra mobile e il controllo dei palindromi.
Rispetto alle liste collegate, i deques spesso forniscono un accesso casuale e un utilizzo della memoria più efficienti, soprattutto nelle implementazioni basate su array. Sebbene le liste collegate doppie possano supportare anche inserimenti e cancellazioni a tempo costante a entrambe le estremità, normalmente comportano un sovraccarico di memoria aggiuntivo a causa dell’archiviazione dei puntatori e possono soffrire di prestazioni di cache inferiori. I deques basati su array, come implementato in librerie come Libreria Standard C++ e Libreria Standard Python, utilizzano buffer circolari o array segmentati per ottenere operazioni a tempo costante ammortizzate a entrambe le estremità, mantenendo al contempo una migliore località di riferimento.
Tuttavia, i deques non sono sempre la scelta ottimale. Per scenari che richiedono frequenti inserimenti e cancellazioni nel mezzo della collezione, strutture dati come alberi bilanciati o liste collegate potrebbero essere preferibili. Inoltre, l’implementazione sottostante di un deque può influenzare le sue caratteristiche di prestazione, con i deques basati su array che eccellono nella velocità di accesso e nell’efficienza della memoria e i deques basati su liste collegate che offrono prestazioni più prevedibili per il ridimensionamento dinamico.
In sintesi, i deques forniscono un’alternativa versatile ed efficiente a stack, code e liste collegate per molti casi d’uso, ma la scelta della struttura dati dovrebbe essere guidata dai requisiti specifici dell’applicazione e dai compromessi di prestazione coinvolti.
Errori Comuni e Migliori Pratiche
Quando si lavora con le strutture dati deque (coda a doppio termine), gli sviluppatori spesso incontrano diversi errori comuni che possono influenzare le prestazioni e la correttezza. Un problema frequente è il cattivo uso delle implementazioni sottostanti. Ad esempio, in linguaggi come Python, utilizzare una lista come deque può portare a operazioni inefficienti, specialmente quando si inseriscono o si cancellano elementi all’inizio, poiché queste sono operazioni O(n). Invece, è meglio utilizzare implementazioni specializzate come collections.deque di Python, che fornisce una complessità temporale O(1) per le operazioni di aggiunta e rimozione a entrambe le estremità.
Un altro errore è trascurare la sicurezza dei thread negli ambienti concorrenti. Le implementazioni standard di deque non sono intrinsecamente sicure per i thread, quindi quando più thread accedono a un deque, devono essere utilizzati meccanismi di sincronizzazione come i lock o varianti sicure per i thread (ad esempio, Java’s ConcurrentLinkedDeque) per prevenire condizioni di competizione.
Le migliori pratiche includono sempre considerare i modelli di utilizzo attesi. Ad esempio, se è necessario un accesso casuale frequente, un deque potrebbe non essere la scelta ottimale, poiché è ottimizzato per le operazioni alle estremità piuttosto che nel mezzo. Inoltre, prestare attenzione all’utilizzo della memoria: alcune implementazioni di deque utilizzano buffer circolari che potrebbero non ridursi automaticamente, portando potenzialmente a un consumo di memoria più elevato se non gestito correttamente (Riferimento C++).
In sintesi, per evitare errori comuni, seleziona sempre l’implementazione deque appropriata per il tuo linguaggio e caso d’uso, garantisci la sicurezza dei thread quando necessario e sii consapevole delle caratteristiche di prestazione e dei comportamenti di gestione della memoria della struttura dati scelta.
Ottimizzazione degli Algoritmi con i Deques
I deques (code a doppio termine) sono strutture dati potenti che possono ottimizzare significativamente alcuni algoritmi consentendo inserimenti e cancellazioni a tempo costante da entrambe le estremità. Questa flessibilità è particolarmente vantaggiosa in scenari in cui sono necessarie sia operazioni di stack che di coda, o in cui gli elementi devono essere gestiti in modo efficiente sia dalla parte anteriore che posteriore di una sequenza.
Un esempio prominente è il problema del massimo nella finestra scorrevole, in cui un deque viene utilizzato per mantenere un elenco di massimi candidati per una finestra mobile su un array. Aggiungendo in modo efficiente nuovi elementi in fondo e rimuovendo elementi obsoleti dalla parte anteriore, l’algoritmo raggiunge una complessità temporale lineare, superando gli approcci naivi che richiederebbero cicli nidificati e comporterebbero complessità quadratica. Questa tecnica è ampiamente utilizzata nell’analisi delle serie temporali e nell’elaborazione dei dati in tempo reale (LeetCode).
I deques ottimizzano anche gli algoritmi di ricerca in ampiezza (BFS), soprattutto in varianti come il 0-1 BFS, dove i pesi degli archi sono limitati a 0 o 1. Qui, un deque consente all’algoritmo di spingere i nodi all’inizio o alla fine in base al peso dell’arco, garantendo un ordine di attraversamento ottimale e riducendo la complessità complessiva (CP-Algorithms).
Inoltre, i deques sono strumentali nell’implementare sistemi di cache (come le cache LRU), dove gli elementi devono essere spostati rapidamente all’inizio o alla fine in base ai modelli di accesso. Le loro operazioni efficienti li rendono ideali per questi casi d’uso, come visto nelle implementazioni della libreria standard come collections.deque di Python.
Conclusione: Quando e Perché Usare i Deques
I deques (code a doppio termine) offrono una combinazione unica di flessibilità ed efficienza, rendendoli uno strumento essenziale nel toolkit di un programmatore. Il loro principale vantaggio risiede nel supporto per inserimenti e cancellazioni a tempo costante da entrambe le estremità, il che non è possibile con code o stack standard. Questo rende i deques particolarmente adatti per scenari in cui gli elementi devono essere aggiunti o rimossi sia dalla parte anteriore che dalla parte posteriore, come nell’implementazione di algoritmi a finestra mobile, nella pianificazione dei compiti o nelle operazioni di annullamento nelle applicazioni software.
Scegliere un deque rispetto ad altre strutture dati è più vantaggioso quando la tua applicazione richiede accesso e modifiche frequenti a entrambe le estremità della sequenza. Ad esempio, negli algoritmi di ricerca in ampiezza (BFS), i deques possono gestire in modo efficiente i nodi da esplorare. Allo stesso modo, nei meccanismi di caching come la cache Least Recently Used (LRU), i deques aiutano a mantenere l’ordine di accesso con un costo minimo. Tuttavia, se il tuo caso d’uso comporta accessi casuali frequenti o modifiche nel mezzo della sequenza, potrebbero essere più appropriate altre strutture come array dinamici o liste collegate.
I linguaggi e le librerie di programmazione moderni forniscono implementazioni robuste di deques, come collections.deque di Python e std::deque della Libreria Standard C++, garantendo prestazioni ottimizzate e facilità d’uso. In sintesi, i deques sono la struttura da scegliere quando hai bisogno di operazioni veloci e flessibili su entrambe le estremità di una sequenza, e la loro adozione può portare a un codice più pulito ed efficiente in una vasta gamma di applicazioni.
Fonti e Riferimenti
- ISO C++ Foundation
- Python Software Foundation
- GeeksforGeeks
- Wikipedia
- Java ArrayDeque
- The Linux Kernel Archives
- CP-Algorithms